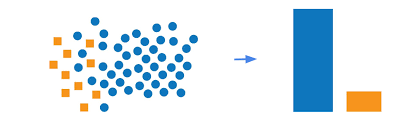
imbalance data
what is it?
Imbalanced data is when one group in your data is much bigger than others. For example, in a survey, 95% of people might like pizza, but only 5% like sushi. best examples of this type of data is the detection of cancer and financial fraud.
why it is bad for ML model?
This can make your machine learning model focus on the big group (pizza) and ignore the small one (sushi). so your model can not predict a proper answer.
how solve it?
To fix it, you can add more data for the small group, cut down the big group, or make fake data with a tool like SMOTE. You can also use special checks to make sure your model notices the small group. Fixing imbalanced data is important for things like finding rare opinions or spotting unusual events.